Introduction to Rust whatlang library and natural language identification algorithms
Serhii Potapov July 30, 2017 #rust #nlp #whatlangI'd like to announce a new Rust library whatlang. Its purpose is to detect natural languages by a given text. Let me show you a quick example:
extern crate whatlang;
use detect;
The output:
Detected language: deu
Script: Latin
Is reliable: true
So, we can see, that library successfully detect short German sentence and we can even trust this information.
You probably noticed, that we had to unwrap info, it's because detect function returns Option<Info>.
It may return None, if the text does not contain any valuable information for language detection
(e.g. numbers or punctuations).
How does it work?
There are two steps:
- Identify a script (writing system)
- Identify a language based using trigram language profiles
Script identification
This part is very simple. We just iterate over the string by characters, and a script that has the most characters in the text is the winner. Scripts are presented in UTF-8 as non-overlapping unicode blocks. You can find information about them in the Internet, here is for example Wikipedia article about Basic Latin block.
Trigram based language detection
You probably know, that every written language has it's own statistic characteristics. For example in English text the most used letters are:
e- 12.7%t- 9%a- 8.2%
And so on. So let's say, if we have a big text with frequency of occurrence of "e" equal 12.7%, "t" equal 9%, and "a" equal 8.2%, we may claim that this text is written in English.
The idea here is similar, but with trigrams.
What is a trigram?
A trigram is a particular case of n-gram, that consists of three items. Instead of long words, I better give you an example. Let's say we have the following text:
love it
Trigrams for this text would be: _lo, lov, ove, ve_, e_i, _it, it_.
The underscore character _ here just represents the word boundaries.
Still how does it work?
The library keeps a list of 300 the most frequent trigrams for every language, sorted by frequency. This is called a language profile. For an input text, we calculate trigrams and sort them by frequency, and after that we compare this with the known language profiles. The language, that has the most similar profile to the profile of the input text is the winner. This idea was presented in the whitepaper Cavnar and Trenkle '94: N-Gram-Based Text Categorization' and I it's a must-read if one wants to understand some algorithmic details.
How is_reliable calculated?
It is based on the following factors:
- How many unique trigrams are in the given text
- How big is the difference between the first and the second(not returned) detected languages? This metric is called
ratein the code base.
Therefore, it can be presented as a 2D space with threshold functions, that splits it into "Reliable" and "Not reliable" areas. This function is a hyperbola and it looks similar to the following one:
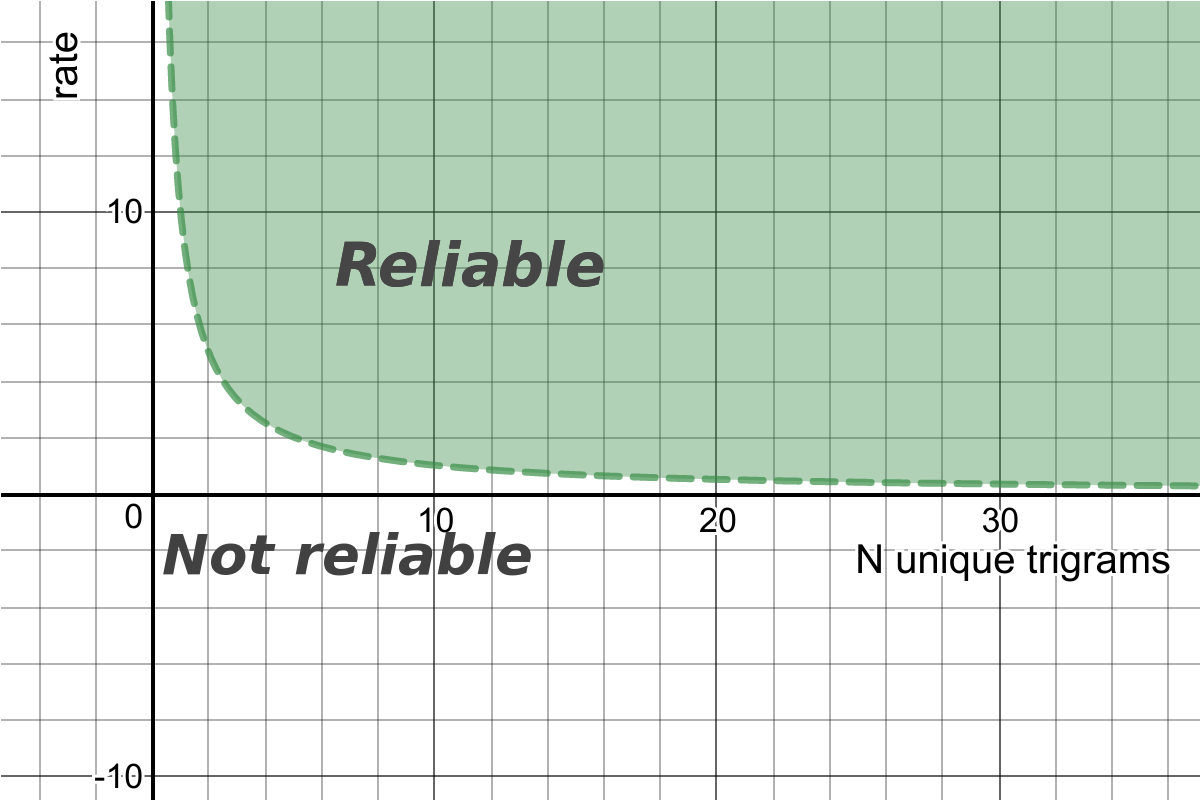
Meaning, the more unique N-grams are in the given text (which correlates with the text length), the more chances to get reliable result, which we can trust.
Advantages and disadvantages of the trigram approach
Advantages:
- Simple
- Fast
- Memory and CPU efficient
- Generic approach that works well for all languages regardless the their grammar
Disadvantages:
- May provide falsy results for short texts (smaller than 200-300 letters). Whatlang tries to compensate this with
is_reliableattribute.
Alternative approaches
One of other approaches I know is to split input text by words, and lookup the words in language dictionaries. This approach may provide better results for short texts, but it's much more complex in its implementation and slower. This would require storing all the words in a database or bloom filters.
For the best ultimate (and pretty complex) solution one may implement a hybrid appoach: use the trigram algorithm for long texts and use dictionary lookup for short texts.
Conclusion
It was a small introduction to whatlang library and language identification algorithms. For information how to use the library (e.g. set a blacklist languages) please check the documentation.
The next step will be porting the library to C language. There is a ticket for this. If I manage to do it, I'll write another article.
Thanks for the reading.
P.S. Your feedback is welcome.